

Machine learning algorithms come with the promise of being able to figure out how to perform important tasks by learning from data, i.e., generalizing from examples without being explicitly told what to do. This means that the higher the amount of data, the more ambtious problems can be tackled by these algorithms. However, developing successful machine learning applications requires quite some “black art” that is hard to find in text books or introductory courses on machine learning.
I recently stumbled upon a great research paper by Professor Pedro Domingos that puts together lessons learned by machine learning researchers and practitioners. In this post, I am going to walkthrough those lessons with you.
Get ready to learn about: pitfalls to avoid, important issues to focus on, and answers to some common questions.
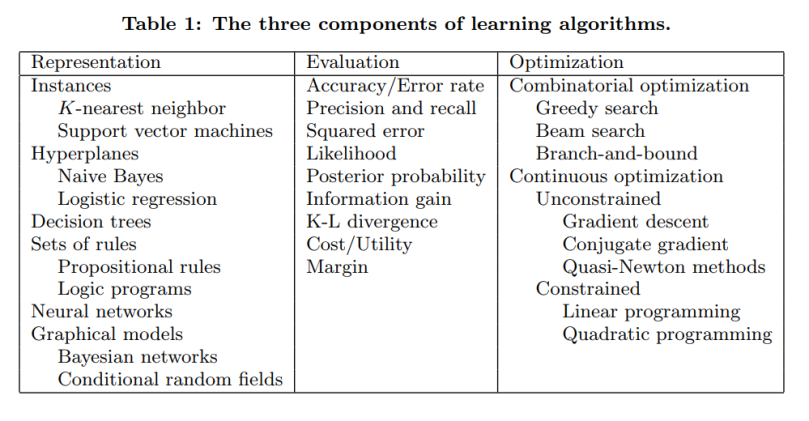
1. Learning = Representation + Evaluation + Optimization
You have an application and you think machine learning might be a good fit for it. Now, once enter the world of machine learning, there are tons of learning algorithms available and hundreds more published each year. Which one to use?

The key to not getting lost in this huge space is to understand that the recipe of all learning algorithms consists of three core ingredients:
- Representation: The input data, i.e., features to use, the learner and the classifier must be must be represented in a language that the computer can understand. The set of classifiers that the learner can possibly learn is called the hypothesis space of the learner. If a classifier is not in the hypothesis space, it cannot be learned.
Clarification note: What do we mean by classifier vs learner? Let’s say you have training data and from that data using a program you build another program (a model) e.g., a decision tree. Learner would be the program which builds the decision tree model from the input data, while the decision tree model would be the classifier (something that is able to give us predicted outputs for each instance of the input data).
- Evaluation: An evaluation function is needed to distinguish good classifiers from bad ones. The evaluation function used internally by the algorithm can be different from our external evaluation metric that we want the classifier to optimize (for ease of optimization and due to the issues discussed later)
- Optimization: Finally, we need a method to search among the classifiers so that we can pick the best one. The choice of optimization technique is key to the efficiency of the learner. It is common to start out using off-the-shelf optimizers. You can later replace them by custom-designed ones, if needed.
The table below shows some common examples of each of these three components.
2. It’s Generalization that Counts
The fundamental goal of machine learning is to generalize beyond the examples in the training set. Because, no matter how much data we have, it is very unlikely that we will see those exact examples again at test time. Doing well on the training set is easy. The most common mistake among beginners is to test on the training data and have the illusion of success. If the chosen classifier is then tested on new data, it is often no better than random guessing. So, set some of the data aside from the beginning, and only use it to test your chosen classifier at the very end, followed by learning your final classifier on the whole data.
Of course, holding out data reduces the amount available for training. This can be mitigated by doing cross-validation: randomly dividing your training data into (say) ten subsets, holding out each one while training on the rest, testing each learned classifier on the examples it did not see, and averaging the results to see how well the particular parameter setting does.
3. Data Alone is Not Enough
When generalization is the goal, we bump into another major consequence: data alone is not enough, no matter how much of it you have. Say we want to learn a boolean function (yes/no classification) of 100 variables from a million examples. This means 2^100 − 10^6 examples whose classes you do not know. How can this beat flipping a coin without any more information at hand?
Sounds like we are stuck, right? Luckily, the functions we want to learn in the real world are not drawn uniformly from the set of all mathematically possible functions! In fact, very general assumptions — like similar examples having similar classes — are a large reason why machine learning has been so successful.
This means that domain knowledge and an understanding of your data are important in making the right assumptions. The need for knowledge in learning should not be surprising. Machine learning is not magic; it can’t get something from nothing. What it does is get more from less. Programming, like all engineering, is a lot of work: we have to build everything from scratch. Learning is a more like farming, which lets nature do most of the work. Farmers combine seeds with nutrients to grow crops. Learners combine knowledge with data to grow programs.
4. Overfitting Has Many Faces
The problem of overfitting is the bugbear of machine learning. When your learner outputs a classifier that is 100% accurate on the training data but only 50% accurate on test data, when in fact it could have output one that is 75% accurate on both, it has overfitted.
Everyone in machine learning knows about overfitting, but it comes in many forms that are not immediately obvious. One way to understand overfitting is by decomposing generalization error into bias and variance.
Bias is a learner’s tendency to consistently learn the same wrong thing. Variance is the tendency to learn random things irrespective of the real signal. This can be understood better by the darts analogy as in the image below:
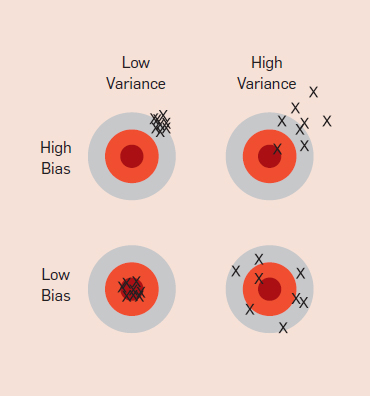
For example, a linear learner has high bias, because when the division between two classes is not a clear cut hyperplane, the learner is unable to induce the relation correctly. Decision trees don’t have this problem because they are flexible in their learning approach. But on the other hand, they can suffer from high variance — decision trees learned on different training data sets for the same task are often very different, when in fact they should be the same.
Now, how to deal with overfitting?
Cross-validation can come to rescue here, for example by using it to choose the best size of the decision tree to learn. However, note that there is again a catch here: if we use it to make too many parameter choices it can itself start to overfit and we are back into the same pitfall.
Besides cross-validation, there are many methods to combat overfitting. The most popular one is adding a regularization term to the evaluation function. Another option is to perform a statistical significance test like chi-square to analyze if adding more complexity has any impact on the class distribution. One important point here though is that no particular technique “solves” the overfitting problem. We can for instance avoid overfitting (variance) by falling into the opposite error of underfitting (bias). Simultaneously avoiding both requires learning a perfect classifier, and there is no single technique that will always do best (no free lunch).
5. Intuition Fails in High Dimensions
After overfitting, the biggest problem in machine learning is the curse of dimensionality. This expression means that many algorithms that work fine in low dimensions become intractable when the input is high-dimensional. Generalizing correctly becomes exponentially harder as the dimensionality (i.e., number of features) of the examples grow, because a fixed-size training set covers a tiny fraction of the input space (possible combinations become huge). But this is what makes machine learning both necessary and hard. As you can see in the image below, even as we transition from 1-D to 3-D, the job of being able to tell the different examples apart seems to start becoming harder and harder — in high dimensions all examples start looking alike.
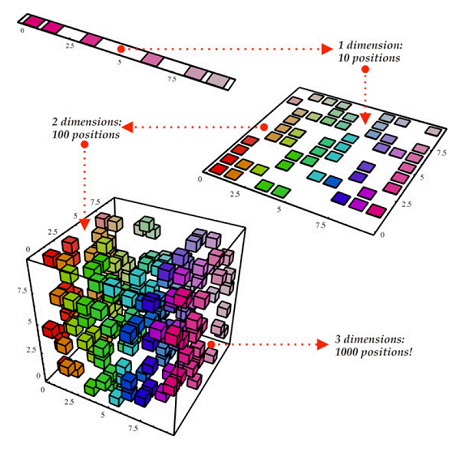
The general problem here is that our intuitions, which come from a 3-D world, fail us in high-dimensions. For instance, most of the volume of a high-dimensional orange is in the skin, not the pulp!
For some more mind boggling: if a constant number of examples is distributed uniformly in a high-dimensional hypercube, and if we approximate a hypersphere by inscribing it in a hypercube, in high dimensions almost all the volume of the hypercube is outside the hypersphere. And this is bad news. Because in machine learning, shapes of one type are often approximated by shapes of another.
Clarification Note: If you are confused by all the “hypes of the hypers”, hypersphere inside a hypercube, looks like this in two and three dimensions:

So as you can understand now, building a classifier in 2 or 3 dimensions is easy, but in high dimensions, it’s hard to understand what is happening. This, in turn, makes it difficult to design a good classifier. In fact, we often fall into the trap of thinking that gathering more features never hurts, since at worst they provide no new information about the class. But in fact, their benefits may be outweighed by the curse of dimensionality.
Take away: next time when you consider adding more features, do consider the potential problems that might arise when your dimension becomes too big.
6. Feature Engineering is the Key
At the end of the day, some machine learning projects succeed and some fail. What makes the difference? Easily the most important factor is the features used. If you have many independent features that each correlate well with the class, learning is easy. On the other hand, if the class is based on a recipe that requires handling the ingredients (features) in a complex way before they can be used, things become harder — feature engineering is basically about creating new input features from your existing ones.
Very often the raw data does not even come in a form ready for learning. But you can construct features from it that can be used for learning. In fact, this is typically where most of the effort in a machine learning project goes. It is often also one of the most interesting parts, where intuition, creativity and “black art” are as important as the technical stuff.
First-timers are often surprised by how little time in a machine learning project is spent actually doing machine learning. But it makes sense if you consider how time-consuming it is to gather data, integrate it, clean it and pre-process it, and how much trial and error can go into feature design. Also, machine learning is not a one-shot process of building a dataset and running a learner, but rather an iterative process of running the learner, analyzing the results, modifying the data and/or the learner, and repeating. Learning is often the quickest part of this, but that’s because we’ve already mastered it pretty well! Feature engineering is more difficult because it’s domain-specific, while learners can be largely general-purpose. Of course, one of the holy grails of machine learning is to automate more and more of the feature engineering process.

7. More Data Beats a Cleverer Algorithm
Suppose you’ve constructed the best set of features you can, but the classifiers you’re getting are still not accurate enough. What can you do now? There are two main choices:
design a better learning algorithm, or gather more data (more examples, and possibly more raw features). Machine learning researchers would go for improving the design, but in the practical world the quickest path to success is often to just get more data.
As a rule of thumb, a dumb algorithm with lots and lots of data beats a clever one with modest amounts of it.
In computer science, often the two main limited resources are time and memory. In machine learning, there is a third one: training data. Among the three, today the main bottleneck is usually time — tons of data is available, but there is not enough time to process it, so it goes unused. This means that in practice simpler classifiers end up reaching the finale, because complex ones take too long to learn.
Part of the reason why using cleverer algorithms doesn’t end up giving much superior results is because at the end of the day they are all doing the same— all learners essentially work by grouping nearby examples into the same class; the key difference is in the meaning of “nearby.” When we have non-uniformly distributed data, even if complex learners can produce very different boundries to classify results, they still end up making the same predictions in the important regions (the region with a high number of training examples, and therefore also where most text examples are likely to appear). As you can see in the image below, whether a fancy curve, a straight line or a stepwise boundry, we can end up with the same predictions:

As a rule, try the simplest learners first (e.g., naive Bayes before logistic regression, k-nearest neighbor before support vector machines). More sophisticated learners are enticing, but they are usually harder to use, because they have more knobs you need to turn to get good results, and because their internals are more like black boxes.
8. Learn Many Models, Not Just One
In the early days of machine learning, efforts went into trying many variations of many learners and still selecting just the best one. But then researchers noticed that, if instead of selecting the best variation found, we combine many variations, the results are better — often much better — and at little extra effort for the user. Creating such model ensembles is now very common:
- In the simplest technique, called bagging, we use the same algorithm but train it on different subsets of original data. In the end we just average answers or combine them by some voting mechanism.
- In boosting, learners are trained one by one sequentially. Each subsequent one paying most of its attention to data points that were mispredicted by the previous one. And we continue until we are satisfied with the results.
- In stacking, the output of different independent classifiers become the input of a new classifier which gives the final predictions.
In the Netflix prize, teams from all over the world competed to build the best video recommender system. As the competition progressed, teams found that they obtained the best results by combining their learners with other teams’, and merged into larger and larger teams. The winner and runner-up were both stacked ensembles of over 100 learners, and combining the two ensembles further improved the results. Together is better!
9. Theoretical Guarantees are Not What They Seem
Machine learning papers are full of theoretical guarantees. What should we make of these guarantees? Induction is traditionally contrasted with deduction: in deduction, you can guarantee that the conclusions are correct; in induction, all bets are off. One of the major developments of recent decades has been the realization that in fact, we can have guarantees on the results of induction, given we are willing to accept probabilistic guarantees.
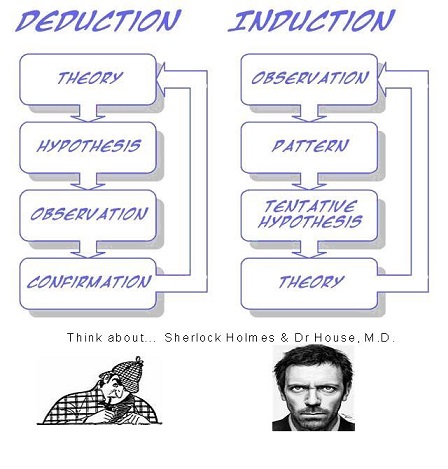
For example, we might have a guarantee that if given a large enough training set, with high probability, our learner will either return a hypothesis that generalizes well or be unable to find a consistent hypothesis.
Another common type of theoretical guarantee is, given infinite data, the learner is guaranteed to output the correct classifier. In practice, because of the bias-variance tradeoff we discussed earlier, if learner A is better than learner B given infinite data, B is often better than A given finite data.
The main role of theoretical guarantees in machine learning is not as a criterion for practical decisions but as a source of understanding algorithm design.
10. Simplicity Does Not Imply Accuracy
In machine learning, Occam’s razor is often taken to mean that, given two classifiers with the same training error, the simpler of the two will likely have the lowest test error.
But this is not true and we saw a counter-example earlier: the generalization error of a boosted ensemble continues to improve by adding classifiers even after the training error has reached zero. Contrary to intuition, there is no necessary connection between the number of parameters of a model and its tendency to overfit. That said, in machine learning, a simpler hypotheses should still be preferred because simplicity is a virtue in its own right and not because it implies accuracy.
11. Representable Does Not Imply Learnable
Just because a function can be represented does not mean it can be learned. For example, standard decision tree learners cannot learn trees with more leaves than there are training examples.
Given finite data, time and memory, standard learners can learn only a tiny subset of all possible functions, and these subsets are different for learners with different representations. So the key take away here is that it pays to try different learners (and possibly combine them).
12. Correlation Does Not Imply Causation
We have all heared that correlation does not imply causation but still people frequently have a tendency to conclude that correlation implies causation.
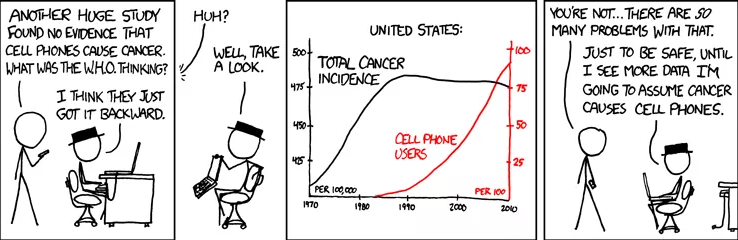
Often the goal of learning predictive models is to use them as guides to action. If we find that beer and diapers are often bought together at the supermarket, then perhaps putting beer next to the diaper section will increase sales. But unless we do an actual experiment it’s difficult to tell if this is true. Correlation is a sign of a potential causal connection, and we can use it as a guide to further investigation and not as our final conclusion.
Conclusion
Like any discipline, machine learning has a lot of “folk wisdom” that can be hard to come by but is crucial for success. And thanks to Professor Domingos, we have gained some of that wisdom today. I hope you found this walkthrough helpful. Let me know your thoughts in the comment section below.
. . .
If you enjoyed reading this post, spread the knowledge by sharing this with others who you think might benefit from this 
